*역자주: 기계 학습에 대해 공부하던 중 좋은 글을 발견했습니다. 기계 학습(Machine Learning)을 공부하는 한국분들을 위해 한국어로도 번역하면 좋겠다고 생각했습니다.
그래서 저자인 Adam Geitgey에게 허락을 받고 번역을 진행했습니다. 가능한 기존에 통용되는 용어로 번역하려고 했습니다만, 잘못되거나 부족한 부분이 있다면 언제든 알려주십시오. 계속해서 정확하게 업데이트하겠습니다.
이 글과 관련하여 의견이나 질문이 있으시면 Jongdae.Lim@gmail.com으로 메일 주시기 바랍니다. 감사합니다.
사람들이 기계 학습(Machine Learning)에 대해 이야기하는 것을 들어 봤지만, 그게 무슨 뜻인지는 명확하지는 않은가요? 동료들과 대화할 때 머리만 끄덕이고 있는 내 모습에 지쳤습니까? 그럼 이제 바꿔봅시다!
이 글은 기계 학습에 대해 궁금한 점은 있지만 어디서부터 시작해야할지 모르는 분들을 위한 안내서입니다. 위키 피디아의 글을 읽고 좌절하고 포기해버린 많은 사람들은 누군가 좀더 쉬운 설명을 해주길 바란다고 생각합니다. 그래서 이글을 쓰게 되었습니다.
이 글의 목표는 누구에게나 쉽게 다가가는 데 있습니다 — 이는 글에 많은 일반화가 있음을 의미합니다. 하지만 어떻습니까? 그래서 더 많은 사람들이 ML에 관심을 가지게 된다면, 목표를 달성한 것입니다.
기계 학습(Machine Learning)이란 무엇인가?
기계 학습은 문제를 해결하기 위한 맞춤 코드(custom code)를 작성하지 않고도 일련의 데이터에 대해 무언가 흥미로운 것을 알려줄 수 있는 일반 알고리즘(generic algorithms)이 있다는 아이디어입니다. 코드를 작성하는 대신 데이터를 일반 알고리즘에 공급하면, 데이터를 기반으로 한 자체 로직이 만들어 지게 됩니다.
예를 들어, 이러한 알고리즘의 한 종류가 분류(classification) 알고리즘입니다. 이 알고리즘을 사용하면 데이터를 서로 다른 그룹으로 분류할 수 있습니다. 손으로 쓴 숫자를 인식하는 데 사용 된 것과 동일한 분류 알고리즘을 그대로 코드 변경없이 사용해서, 이메일을 스팸과 스팸이 아닌 것으로 분류 할 수도 있습니다. 결국 동일한 알고리즘이지만 다른 학습 데이터를 제공하면 다른 분류 로직이 자동으로 만들어지게 됩니다.
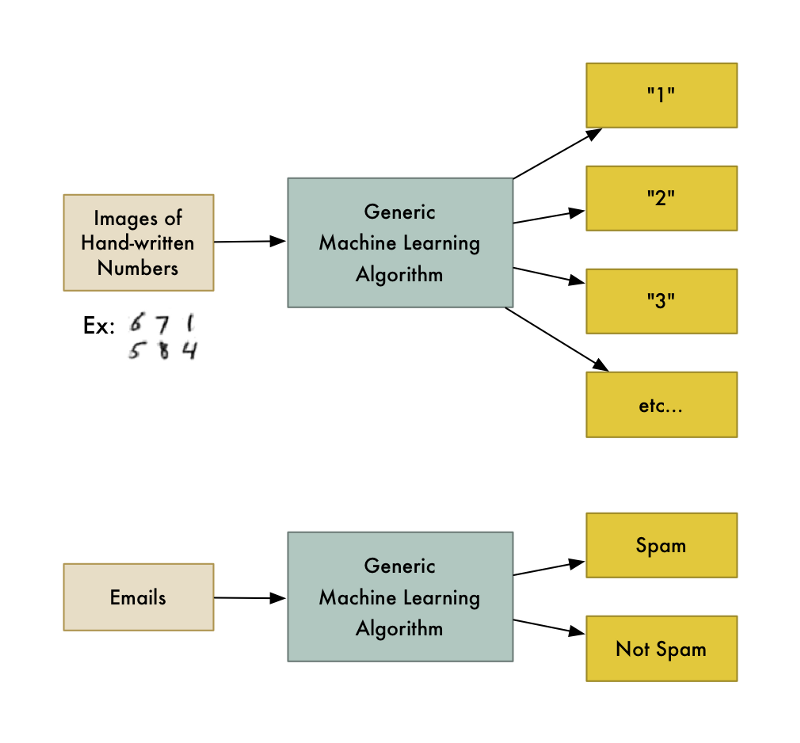
“기계 학습(Machine Learning)”은 이런 종류의 일반 알고리즘(generic algorithms)을 포함하는 포괄적인 용어입니다.
두 종류의 기계 학습 알고리즘
기계 학습 알고리즘은 지도 학습(supervised learning)과 비지도 학습(unsupervised learning)의 두 가지 주요 범주 중 하나로 분류될 수 있습니다. 이 차이는 간단하지만 매우 중요합니다.
지도 학습(Supervised Learning)
당신이 부동산 중개인이라고 가정해 봅시다. 비즈니스가 성장함에 따라 당신을 도와줄 수습 직원을 고용하려고 합니다. 그런데 문제가 있습니다. 당신은 주택을 보기만해도 얼마의 가치가 있는지 잘 알수 있습니다. 그러나 수습 직원들은 당신과 같은 경험이 없으므로 어떻게 주택 가격을 책정해야 하는지 알지 못합니다.
수습 직원을 돕기 위해 (그리고 어쩌면 당신이 휴가를 즐기기 위해), 당신은 주택의 크기, 지역 등을 기준으로 주택 가치를 추정 할 수 있는 작은 앱을 개발하기로 했습니다.
그래서 당신은 누군가가 당신의 도시에서 3 개월 동안 주택을 팔 때마다 그 정보를 기록했습니다. 각 주택의 방의 개수, 평방 피트 크기, 지역 등 세부 정보를 기록했습니다. 그러나 가장 중요한 것은 최종 판매 가격을 기록하는 것입니다.

이 훈련 데이터를 사용해서 해당 지역의 다른 주택이 얼마의 가치가 있는지 추정 할 수있는 프로그램을 만들려고 합니다.

이것을 지도 학습(supervised learning)이라고합니다. 당신은 각각의 주택들이 얼마에 팔렸는지 알고 있습니다. 다시 말해서, 당신은 문제에 대한 답을 알고 있기 때문에 여기에서 반대로 로직을 파악할 수 있습니다.
앱을 제작하기 위해, 각 주택에 대한 훈련 데이터를 기계 학습 알고리즘에 넣어야 합니다. 이 알고리즘은 해당 숫자의 의미를 알아낼 수 있는 수학이 무엇인지 파악하기 위해 노력하게 됩니다.
이것은 마치 모든 연산 기호가 지워진 수학 시험에 대한 해답을 갖고 있는 것과 같습니다.
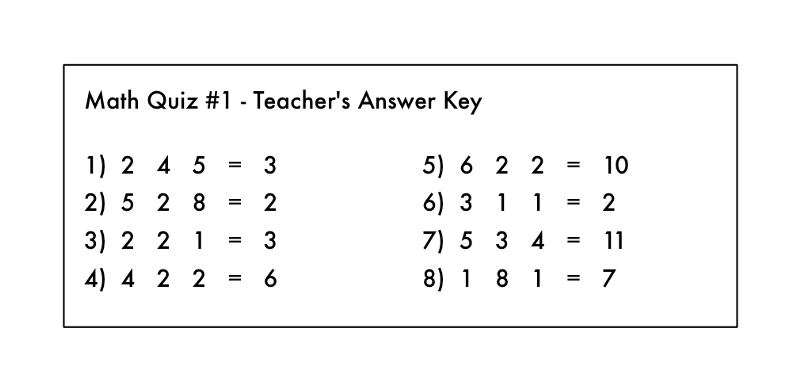
여기에서, 당신은 어떤 종류의 수학 문제가 시험에 있었는지 알아낼 수 있습니까? 당신은 오른쪽에 있는 각각의 답을 얻기 위해 왼쪽에있는 숫자들에 “무언인가를 하면” 된다는 것을 알고 있습니다.
*역자주: 모두 눈치채셨겠지만, 위 수학 퀴즈에서 빠진 기호는 순서대로 *, -(곱하기, 빼기)입니다.
1) 2 * 4 - 5 = 3, 2) 5 * 2 - 8 = 2, 3) 2 * 2 - 1 = 3, …, 8) 1 * 8 - 1 = 7
지도 학습에서, 당신은 컴퓨터가 당신을 위해 그 관계를 해결하도록 내버려 두면 됩니다. 그리고 이 특정 문제들을 해결하기 위해 필요한 수학이 무엇인지 알게되면 같은 유형의 다른 문제에 대해서도 답을 얻을 수 있습니다!
비지도 학습(Unsupervised Learning)
처음 시작했던 부동산 중개업자의 사례로 돌아가 보겠습니다. 각 주택의 판매 가격을 모르는 경우에는 어떻게 될까요? 비록 당신이 알고 있는 정보가 각 집의 크기, 위치 같은 것 뿐이더라도, 당신은 여전히 멋진 일들을 할 수 있습니다. 이것이 바로 비지도 학습입니다.
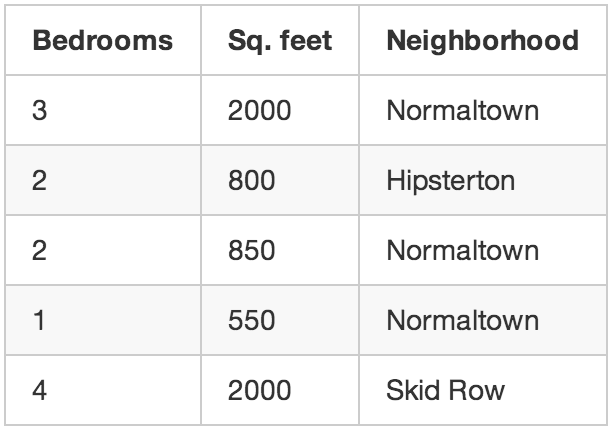
이것은 누군가 종이에 숫자 목록을 주고 “나는 이 숫자가 무엇을 의미하는지 알지 못하지만, 어쩌면 당신은 패턴이나 분류(grouping) 또는 무언가가 있는지 알아낼 수도 있을 겁니다 — 행운을 빕니다!”라고 말하는 것과 같습니다.
그렇다면 이 데이터로 무엇을 할 수 있을까요? 당신은 데이터에서 서로 다른 시장 세그먼트(market segments, 세분시장)를 자동으로 식별하는 알고리즘을 만들 수도 있습니다. 어쩌면 당신은 지역 대학 근처의 주택 구매자는 침실이 많은 작은 집을 좋아지만, 교외의 주택 구매자는 면적이 넓은 침실이 3 개인 집을 선호한다는 사실을 알아낼지도 모릅니다. 이렇게 여러 종류의 고객에 대해 알게되면 마케팅 활동에 직접적으로 도움을 받을 수 있을 것입니다.
당신이 할 수 있는 또 다른 멋진 일은 자동으로 다른 주택들과 다른 특이한 주택을 식별하는 것입니다. 만약 이 특이한 주택들이 거대한 저택이라면 더 많은 수수료를 받을 수 있기 때문에 당신의 최고의 영업사원들을 이 영역에 집중시킬 수 있습니다.
이 글의 나머지는 대부분 지도 학습에 집중하게 될텐데, 그렇다고 해서 비지도 학습이 덜 유용하거나 흥미롭지 않다는 것은 아닙니다. 사실, 비지도 학습은 알고리즘들이 향상됨에 따라 더욱더 중요해 지고 있습니다. 왜냐하면, 비지도 학습이 정확한 답을 가진 라벨이 붙여진 데이터가 아닌 경우에 사용될 수 있기 때문입니다.
현학자들을 위한 노트: 네 맞습니다. 많은 다른 종류의 기계 학습 알고리즘이 있습니다. 그러나 , 여기서부터 시작하는 것도 나쁘지 않습니다.
멋지군요, 그런데 정말로 주택 가격이 얼마인지 “학습”을 통해 추정할 수 있습니까?
인간이기 때문에, 당신의 두뇌는 대부분의 상황에 대해 이해할 수 있으며, 명시적으로 가르쳐 주지 않아도 상황을 어떻게 해결하면 되는지 배울 수 있습니다. 당신이 오랫동안 주택을 판매한다면, 적절한 주택 가격, 주택을 판매하는 가장 좋은 방법, 관심이 있을 고객의 종류 등에 대한 “느낌(feel)”을 본능적으로 갖게될 것입니다. Strong AI 연구의 목표가 바로 이러한 인간의 능력을 컴퓨터로 복제하는 것입니다.
그러나 현재의 기계 학습 알고리즘은 그런 수준은 아닙니다 — 매우 구체적이고 제한적인 문제에 초점을 맞춘 경우에만 동작합니다. 이러한 경우 “학습”에 대한 더 나은 정의는 “약간의 샘플 데이터를 기반으로 특정 문제를 해결하기위한 방정식을 알아내는 것”이 될 수 있습니다.
불행하게도”약간의 샘플 데이터를 기반으로 특정 문제를 해결하기위한 방정식을 알아내는 기계”는 그렇게 좋은 이름은 아닙니다. 그래서 우리는 대신 “기계 학습”이라고 부릅니다.
물론 당신이 앞으로 50년 후에 이 글을 읽고 있고 이미 우리는 Strong AI를 위한 알고리즘을 알아낸 후라면, 여기 있는 글들은 모두 약간 옛날 얘기처럼 보일 것입니다. 그렇다면 이봐요 미래인간, 이제 그만 읽고 로봇 하인에게 샌드위치나 만들라고 하세요.
그럼 프로그램을 작성해 봅시다!
그래서, 앞선 예와 같이 주택의 가치를 추정하는 프로그램을 어떻게 작성 하시겠습니까? 다음 내용을 읽기 전에 잠시 생각해 보세요.
기계 학습에 대해 잘 모른다면, 아마도 당신은 다음과 같이 주택 가격을 추정하기위한 기본 규칙들을 작성하고자 할 것입니다.
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# 담당 지역내 평균 주택 가격은 평방 피트 당 200 달러이다
price_per_sqft = 200
if neighborhood == "hipsterton":
# 하지만 다른 지역은 조금 더 비싸다
price_per_sqft = 400
elif neighborhood == "skid row":
# 그리고 다른 몇몇 지역은 싸다
price_per_sqft = 100
# 주택의 크기를 기반으로 주택 가격을 추정하는 것으로 시작한다
price = price_per_sqft * sqft
# 이제 침실의 개수로 추정치를 조정한다
if num_of_bedrooms == 0:
# 원룸형 아파트는 가격이 싸다
price = price — 20000
else:
# 일반적으로 많은 침실이 있는 주택이 더 비싸다
price = price + (num_of_bedrooms * 1000)
return price
이런 과정을 몇 시간이고 계속하다 보면, 뭔가 그럴듯한 것을 만들어 낼 수도 있습니다. 그러나 당신의 프로그램은 결코 완벽하지 않으며 가격이 변함에 따라 로직을 유지하기가 어려울 것입니다.
당신을 대신해서 컴퓨터가 이 기능을 구현하게 하는 방법이 더 좋지 않을까요? 함수가 정확한 숫자를 반환하는데 누가 뭐라고 하겠습니까:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = <컴퓨터, 나 대신 수학식 좀 만들어줘>
return price
이 문제를 해결할 수 있는 또다른 방법은 가격(price)이 맛있는 스튜(stew)이며 그 재료는 침실의 개수(number of bedrooms), 평방 피트 면적(square footage) 및 지역(neighborhood)이라고 생각하는 것입니다. 각 재료가 최종 가격에 얼마나 많은 영향을 미치는지 파악할 수 있다면, 이 최종 가격을 만들어줄 혼합 재료의 정확한 비율이 있을 것입니다.
이렇게하면 정말 간단하게 (if 와 else가 미친듯이 많았던) 원래 함수를 다음과 같이 줄일 수 있을 것입니다.
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# 이건 한 꼬집 넣고
price += num_of_bedrooms * .841231951398213
# 그리고 저건 한 스픈 정도 넣고
price += sqft * 1231.1231231
# 이건 아마도 한 줌 넣고
price += neighborhood * 2.3242341421
# 그리고 마지막으로, 약간의 소금을 추가
price += 201.23432095
return price
굵은 글씨로 쓰여진 마법의 숫자를 주목하세요 — .841231951398213, 1231.1231231, 2.3242341421 그리고 201.23432095. 이 숫자들이 바로 가중치 입니다. 만약 모든 주택에 적용할 수 있는 완벽한 가중치를 찾아낼 수만 있다면, 우리의 함수는 집값을 예측할 수 있을 것입니다!
최상의 가중치를 알아낼 때 한가지 쉬운 방법은 아마 다음과 같을 것입니다.
Step 1:
먼저 가중치를 1.0로 하고 시작합니다:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# 이건 한 꼬집 넣고
price += num_of_bedrooms * 1.0
# 그리고 저건 한 스픈 정도 넣고
price += sqft * 1.0
# 이건 아마도 한 줌 넣고
price += neighborhood * 1.0
# 그리고 마지막으로, 약간의 소금을 추가
price += 1.0
return price
Step 2:
그리고 알고있는 모든 주택 데이터를 당신의 함수를 통해 실행해보고 각 주택의 정확한 가격과 이 함수가 얼마나 차이가 나는지 살펴보는 것입니다:

예를 들어, 첫번째 주택은 실제로는 $250,000에 판매되었고, 당신의 함수는 $178,000에 판매되었다고 추정한것인데, 이 주택 하나만 보더라도 $72,000만큼 차이가 납니다.
이제 데이터 세트에 있는 각 주택 마다 차이난 가격의 제곱값을 추가해 보겠습니다. 데이터 세트에는 500 개의 주택 판매 정보가 있었고 각 주택에 대해 당신의 함수가 추정한 값과 실제 가격의 차이를 제곱한 값의 총합은 $86,123,373라고 가정해 보겠습니다. 이를 통해 당신이 함수가 현재 얼마나 “잘못되었는지” 알 수 있습니다.
이제, 이 합계를 500으로 나눠서 각 주택별로 얼마나 차이가 나는지 평균값을 구해보겠습니다. 이 평균 오류 값을 이 함수의 비용(cost)이라고 하겠습니다.
당신이 가중치를 잘 조정해서 이 비용을 0으로 만들 수 있다면, 당신의 함수는 완벽지게 됩니다. 다시 말해서, 모든 경우에 대해서 당신의 함수가 입력 데이터를 기반으로 주택 가격을 완벽하게 추정할수 있다는 것을 의미합니다. 네, 다른 가중치를 시도해서 가능한 이 비용을 낮추려는 것, 이것이 바로 우리의 목표입니다.
Step 3:
가능한 모든 가중치를 조합해서 2 단계를 계속 반복합니다. 어떤 조합의 가중치든 비용을 0에 가깝게 만들어 주는 것을 사용하면 됩니다. 이런 가중치를 찾으면 문제를 해결한 것입니다!
깜짝 놀랄 시간
아주 간단하죠? 방금 전 한 일에 대해 정리해 보겠습니다. 당신은 약간의 데이터를 가져와 이를 세 가지의 일반적이고 아주 간단한 단계에 제공한 다음, 해당 지역의 모든 집의 가격을 추정할 수 있는 함수를 만들어 냈습니다. Zillow, 조심하는게 좋을꺼야!
*역자주 : Zillow는 2006년 설립된 미국에서 매우 유명한 온라인 부동산 회사입니다.
그런데 당신을 깜짝 놀라게 할 몇 가지 사실이 더 있습니다:
- 40년 넘게 많은 분야(예를 들어, 언어학/번역)에서 연구한 결과, “숫자로 만든 스튜를 젓는”(제가 막 만들어낸 문장입니다) 이러한 일반 학습 알고리즘이 명시적인 규칙으로 접근하는 실제 사람들의 접근방법을 압도했습니다. 기계 학습의 이 “멍청한” 접근방법이 결국 인간 전문가들을 이기고 말았습니다.
*역자주: “숫자로 만든 스튜를 젓는” (“stir the number stew”)의 뜻은 앞서 변수들을 스튜의 재료로 가정하고 가중치의 조합을 찾아내는 아주 단순한 과정을 뜻합니다.
2. 당신이 만든 최종 함수는 실제로 완전히 바보입니다. “평방 피트”또는 “침실”이 무엇인지조차 알지 못합니다. 이 함수가 아는 것이라고는 정답을 얻기위해 이러한 숫자들의 값을 저어줘야 한다입니다.
3. 당신은 어째서 특정 가중치의 조합이 잘 동작하는지 알지 못하는게 당연합니다. 즉, 당신은 실제로 이해하지 못하는 함수를 작성했지만, 잘 동작하는 것은 증명할 수 있습니다.
4. “sqft”과 “num_of_bedrooms”와 같은 매개변수를 사용하는 대신 예측 함수에 숫자 배열만을 사용한다고 상상해보십시오. 그리고, 각 숫자가 자동차 위에 장착한 카메라로 촬영한 이미지에서 1 픽셀의 밝기를 나타 낸다고 가정해 보겠습니다. 이제 “price”라는 예측을 출력하는 대신 이 함수는 “degrees_to_turn_steering_wheel”이라는 예측을 출력한다고 상상해보세요. 그래요, 당신은 방금 스스로 차를 조종 할 수 있는 함수 만들었습니다!
완전 멋지죠?
Step 3에서 “모든 숫자를 시도해보는 것”은 무슨 뜻인가요?
물론, 실제로 모든 가중치의 모든 조합을 시도해서 가장 잘 작동하는 조합를 찾을 수는 없습니다. 당신이 시도 할 숫자 조합은 무한하기 때문에 당연하게도 영원히 걸릴 것입니다.
이것을 피하기 위해서, 수학자들은 많은 것을 시도하지 않고도 이러한 가중치에 대한 좋은 값을 빨리 찾을 수있는 영리한 방법을 알아냈습니다. 여기 그중 한가지 방법이 있습니다:
먼저, 위 Step 2를 나타내는 간단한 방정식을 작성합니다:
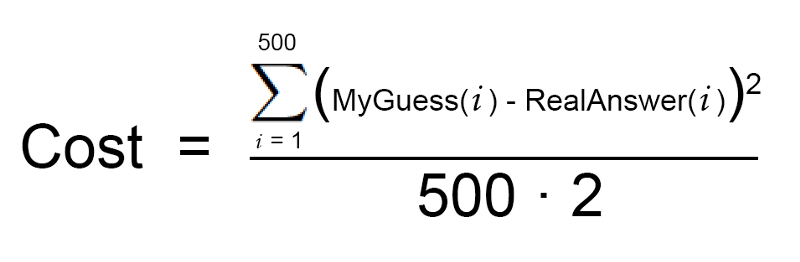
이제 완전히 똑같은 방정식을 재작성해 볼텐데, 대신 기계 학습의 수학 용어를 사용해 보겠습니다.(모르는 용어들은 지금은 그냥 무시하세요) :
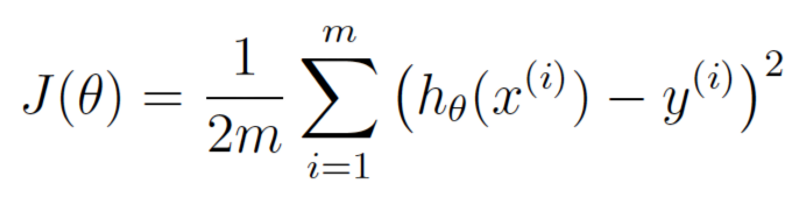
이 방정식은 현재 설정한 가중치에 대해 우리의 가격 추정 함수가 얼마나 차이 나는지를 나타냅니다.
number_of_bedrooms와 sqft에 대한 모든 가능한 가중치 값에 대해 이 비용 방정식을 그래프로 나타내면 다음과 같습니다:
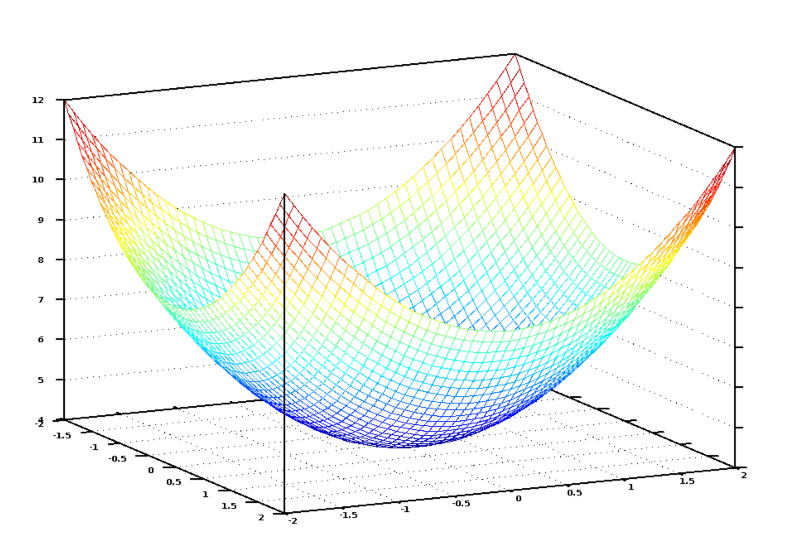
이 그래프에서 파란색의 가장 낮은 지점이 비용이 가장 낮은 곳입니다 — 따라서, 우리의 함수는 조금 잘못되었습니다. 가장 높은 지점들이 가장 잘못된 것입니다. 즉, 우리가 이 그래프의 가장 낮은 지점으로 이동할 수 있는 가중치를 찾는다면, 우리는 답을 찾는 겁니다!
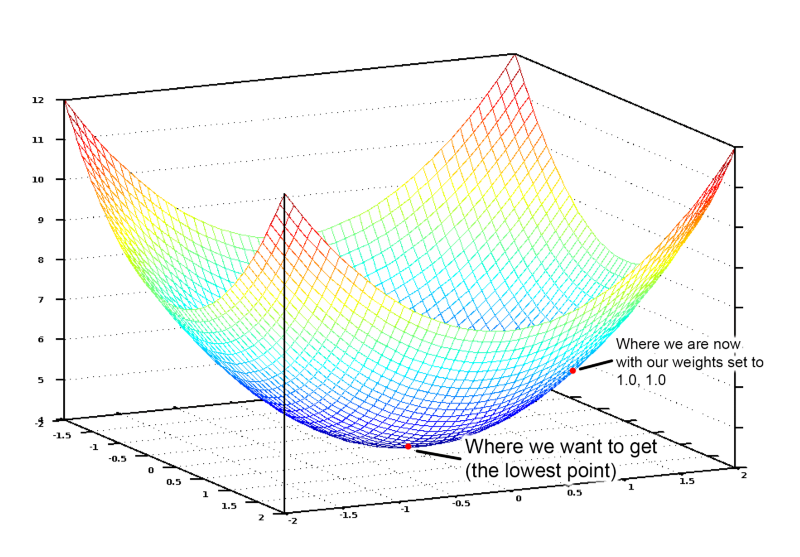
이제 그래프에서 가장 낮은 지점을 향해 “언덕을 걸어 내려 갈 수 있도록” 우리의 가중치를 조정해야 합니다. 만약 우리가 가장 낮은 지점으로 이동하도록 가중치를 조금씩 조정해 나간다면, 결과적으로 너무 많은 다른 가중치를 시도하지 않고도 그곳에 도달하게 될 것입니다.
미적분에 대해 기억을 더듬어 보면, 함수를 미분하면 함수의 특정 지점에 대한 접선의 기울기를 알 수 있다는 것이 생각날 것입니다. 다시 말해서, 미분을 통해 그래프의 특정 지점에 대해 내리막 길이 어느 방향인지 알 수 있습니다. 우리는 이 지식을 이용해 내리막 길로 걸어 내려갈 수 있습니다.
따라서 각 가중치에 대한 비용 함수의 편미분을 계산하고, 각 가중치에서 해당 값을 뺄 수 있습니다. 이를 통해 우리는 언덕 맨 아래로 한 걸음 더 가까이 가게 됩니다. 이 작업을 계속하면 궁극적으로 언덕 맨 아래에 도달하여 가장 좋은 가중치를 얻게됩니다. (이 부분이 이해가 안되어도 걱정하지 말고 계속 읽세요).
사실 이 방법은 함수의 적합한 가중치를 찾는 방법 중에 하나인 배치 기울기 하강(batch gradient descent)에 대한 개괄적인 설명입니다. 세부적인 내용에 대해 배우고 싶다면 좀더 깊이 공부해보십시오.
실제 문제를 해결하기 위해 기계 학습 라이브러리를 사용하면 이러한 모든 작업이 자동으로 수행됩니다. 그러나 어떤 일이 일어나는 지에 대해 잘 이해하고 있는 것은 여전히 유용합니다.
적당히 건너 뛴 내용은 또 어떤 것들이 있나요?
앞서 설명한 3 단계의 알고리즘을 다변수 선형 회귀(multivariate linear regression)라고 부릅니다. 사실 당신은 모든 주택 데이터 값에 대해 딱 맞는 직선 방정식을 계산하는 것입니다. 그리고 이 방정식을 사용해서 이전에 보지 못했던 주택의 판매 가격을 추정할 수 있는 것입니다. 이는 정말이지 강력한 아이디어이며, 당신은 이 방법으로 “진짜” 문제를 해결할 수 있습니다.
그러나 지금까지 설명한 접근 방식이 단순한 경우에는 효과가 있지만, 모든 경우에 동작하지는 않습니다. 한 가지 이유는 집값이 항상 연속적인 직선을 따라갈만큼 단순하지 않기 때문입니다.
다행히도 이를 처리 할 수 있는 많은 방법들이 있습니다. 비선형 데이터 (예를 들어, 신경망(neural networks) 또는 SVMs 과 kernels)를 처리 할 수있는 많은 기계 학습 알고리즘이 있습니다. 선형 회귀(linear regression)를 보다 영리하게 사용해서 더욱 복잡한 선을 맞추는 방법도 있습니다. 이런한 모든 방법에는 최상의 가중치를 찾아야한다는 동일한 기본 아이디어는 여전히 적용되고 있습니다.
정리하자면, 기본 개념은 매우 단순하지만 기계 학습을 적용하고 유용한 결과를 얻으려면 약간의 기술과 경험이 필요합니다. 하지만, 모든 개발자가 배울 수있는 기술입니다!
기계 학습은 마술인가?
컴퓨터 학습 기술을 (필기체 인식과 같은 같이) 어려워 보이는 문제에 얼마나 쉽게 적용 할 수 있는지 알게되면, 당신은 이제 충분한 데이터만 있다면 기계 학습을 적용해서 문제를 해결할 수 있다는 느낌을 가지게 될 것입니다. 단지 데이터만 제공하고 컴퓨터가 마술처럼 데이터에 맞는 방정식을 계산해 주는 것을 감상만 하면 됩니다.
하지만, 기계 학습은 보유한 데이터로 해결 가능한 문제인 경우에만 동작한다는 점을 기억하는 것이 중요합니다.
예를 들어, 각 주택의 화분 종류에 따라 주택 가격을 예측하는 모델을 만들면, 절대로 동작하지 않을 것입니다. 각 집에있는 화분과 주택 판매 가격 사이에는 아무런 관계가 없습니다. 따라서 컴퓨터가 아무리 노력해도 둘 사이의 관계를 결코 추론 할 수 없습니다.
따라서 인간 전문가가 수작업으로 문제를 해결하기 위해 데이터를 사용할 수 없다면, 컴퓨터도 아마 동작하지 않을 것입니다. 바꿔말해, 인간이 해결할 수있는 문제 중에서 컴퓨터가 훨씬 빨리 문제를 해결할 수 있는 것에 집중하는 것이 좋습니다.
기계 학습에 대해 좀더 배울 수 있는 방법
제 생각에, 현재 기계 학습의 가장 큰 문제점은 학계와 상업 연구 그룹의 세상에 있습니다. 실제로 전문가가되지 않고서는 폭 넓은 이해를 하고 싶어하는 사람들을 위한 이해하기 쉬운 자료가 세상에 많지 않습니다. 그러나 매일 조금 나아지고 있습니다.
앤드류 응 (Andrew Ng)의 Coursera에 있는 무료 Machine Learning 수업은 매우 훌륭합니다. 여기에서 시작하는 것을 강력히 추천드립니다. 컴퓨터 전공 학위가 있는 사람과 수학을 아주 조금 기억하는 사람이라면 누구나 수강할 수 있습니다.
또한 SciKit-Learn을 다운로드해서 설치하면 수 많은 기계 학습 알고리즘을 가지고 놀 수 있습니다. 이것은 모든 표준 알고리즘에 대한 “블랙 박스” 버전의 파이썬 프레임워크(python framework)입니다.
이 글이 마음에 들었다면, 제 Machine Learning is Fun! 이메일 리스트에 가입하는 것도 좋습니다! 새롭고 멋진 소식이있을 때만 이메일을 보내 드리겠습니다. 제가 이런 종류의 추가 글을 올릴때가 언제인지 알 수 있는 가장 좋은 방법입니다.
*역자주: 번역글과 관련해 의견 주시려면, 저에게 직접 이메일을 보내시거나 LinkedIn에서 저를 찾으셔도 됩니다.